

写在之前:学校开了一堆专业课,其中包括数字逻辑,离散数学,但就我了解的情况来看,这门课是计算机组成原理的先修课,离散数学应该是为数据结构准备的,不知道为啥要等数据结构学完了再上,而且图论部分只涉及到了一点点。,深知这些枯燥无味的原理课程对以后发展的起着重要作用,所以决定开始啃《深入理解计算机系统》,也就是大名鼎鼎的csapp这本书,书中说:“如果你全力投身学习本书中的概念,完全理解底层计算机系统以及它对应用程序的影响,那么你会步上成为为数不多的“大牛”道路”。这本书的电子版我放在这篇文章的最后面,有兴趣可以下载下来看看(究极高清版本!)
信息:位+上下文
首先下面的这个程序应该每个人都写过的:
#include<stdio.h>
int main() {
printf("hello world");
return 0;
}从源文件到最终的结果输出,大概经过了如下阶段:
预处理阶段:源文件根据#开头的命令,修改源代码文件,比如#include<stdio.h>命令,就是将系统头文件stdio.h的内容直接粘贴到源程序中(所以不建议使用万能头文件)。这次操作结束之后,会得到另一个源程序,以.i作为扩展名。
编译阶段:编译器将hello.i文件翻译成hello.s,它包含一个汇编语言程序。该程序的main函数定义:
main:
subq $8, %rsp
movl $.LCO, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret以上代码每一行都是低级机器语言指令。
汇编阶段:接下来,汇编器将hello.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件hello.o中,这个文件时一个二进制文件。
链接阶段:将所有的函数,比如此程序中的printf函数,都合并到hello.o中,链接器(Id)负责处理这种合并。结果得到hello文件,他是一个可执行文件,可以被加载到内存中,由系统执行。
处理器读并解释存储在内存中的指令:此刻,hello.c源程序已经被编译系统翻译成了可执行文件hello,并存储在磁盘上,如果在Unix系统上运行该文件:
>linux> ./hello
hello, world
linux>shell是一个命令解释器,它输出一个提示符:linux>,等待输入命令行,然后执行这个命令。
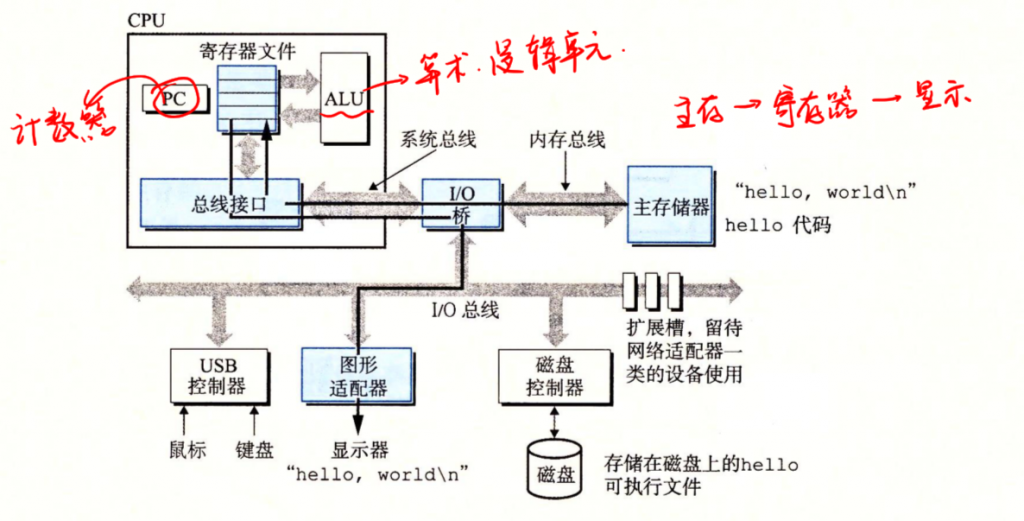
系统的硬件组成
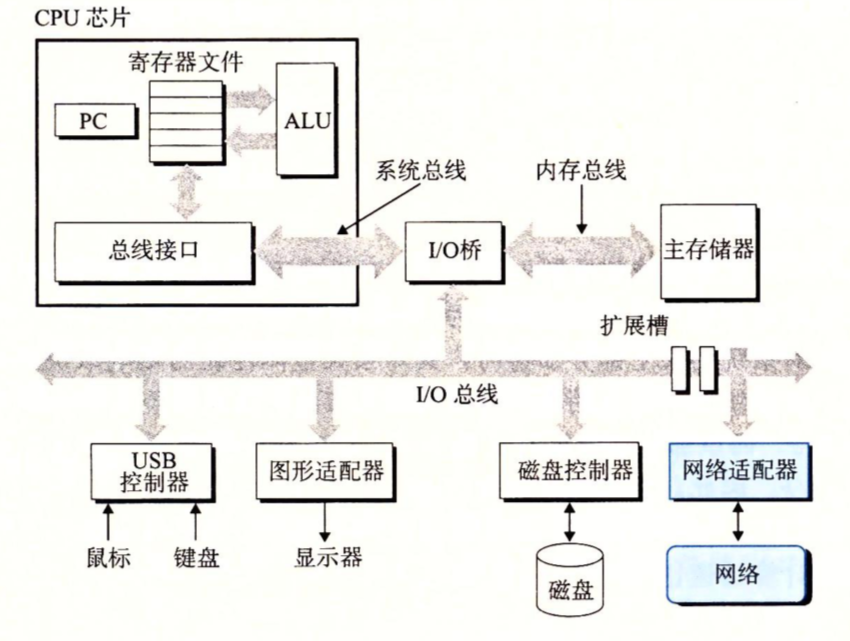
典型系统的硬件组织:

- 总线:贯穿于整个系统的一组电子管道,它携带信息字节并在各个部件间传递。总线被设计成传送定长的字节块,也就是字(word)。字中的字节数是要给基本的系统参数,各个系统中都不相同。现在一般都是8个字节(64位系统)
- I/O设备:输入输出设备是系统与外部世界的联系通道,常见的是键鼠显示器。每个I/O设备都通过一个控制器或适配器与I/O总线相连。控制器与适配器之间的区别主要在于它们的封装方式。控制器是在主板上的,适配器实在主板插槽上的卡。
- 内存:内存是一个临时存储设备,处理器执行程序时,用来存放程序和程序处理的数据。从物理上来说,内存是由一组动态随机存取存储器(DRAM),也就是Dynamic RAM。从逻辑上来说,存储时是一个线性的字节数组,每个字节都有属于自己的地址,这些地址是从0开始的。
- 处理器:CPU:解释或执行存储在内存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(寄存器),或称为程序计数器(PC)。在任何时刻,PC指向主存中的某条机器语言指令。从系统通电开始到断电,处理器一直在不断执行计数器指向的指令,再更新程序计数器,使其指向下一条指令(这也是为什么称cpu为电脑的心脏)。
运行hello程序
初始时,shell程序执行它的指令,等待我们输入一个命令。当我们在键盘上输入./hello后,shell程序将字符逐一读入到寄存器,再把它放到内存中。当我们在键盘上敲回车时,shell程序就知道我们已经结束了命令的输入,然后shell执行一系列指令来加载可执行的hello文件,这些指令将hello目标文件中的代码和数据从磁盘复制到内存。数据包括最终挥别输出的字符串“hello world\n”。
当目标文件hello中的代码和数据被加载到内存时,处理器就开始执行hello程序的main程序中的机器语言指令,这些指令将“hello, world\n”字符串中的字节从主存复制到寄存器文件,再从寄存器文件中复制到显示设备,最终会显示在屏幕上,步骤如下:
高速缓存的重要
可以看出,在我们刚刚的操作中,有很多信息被复制来复制去,而这些信息的复制就是开销,减慢了程序的运行速度。
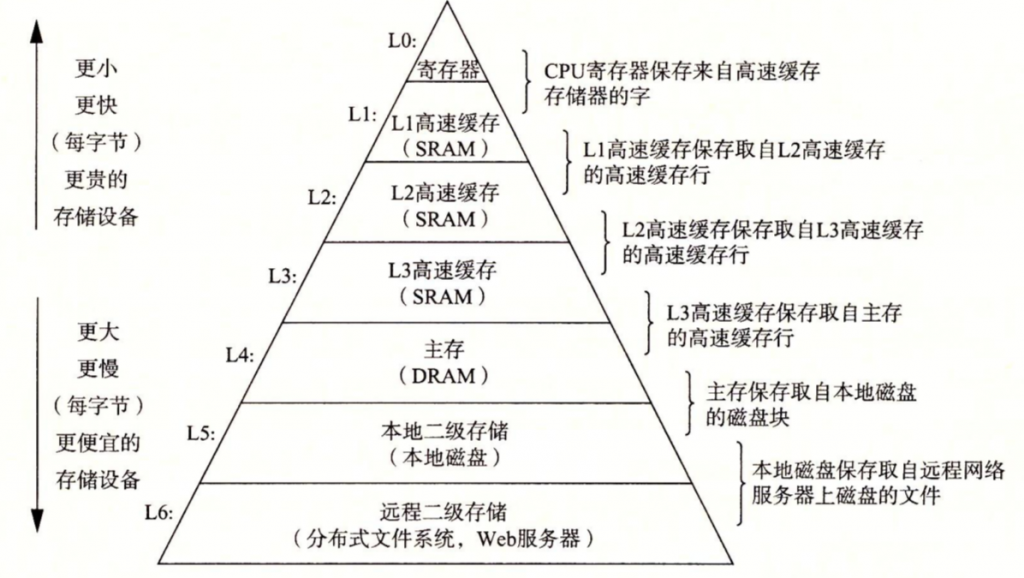
根据机械原理:较大的存储设备要比较小的存储设备运行得慢,而快速设备的造假远高于同类低速设备。类似的,一个典型的寄存器文件只存储几百字的信息,而主存里可存放几十亿字节。然而,处理器从寄存器文件中读数据比从主存中读取几乎要快100倍。
针对这种处理器与贮存之间的差异,系统设计者采用更快的存储设备:高速缓存存储器:cache,作为暂时的集结区域,存放最近可能需要处理的信息。
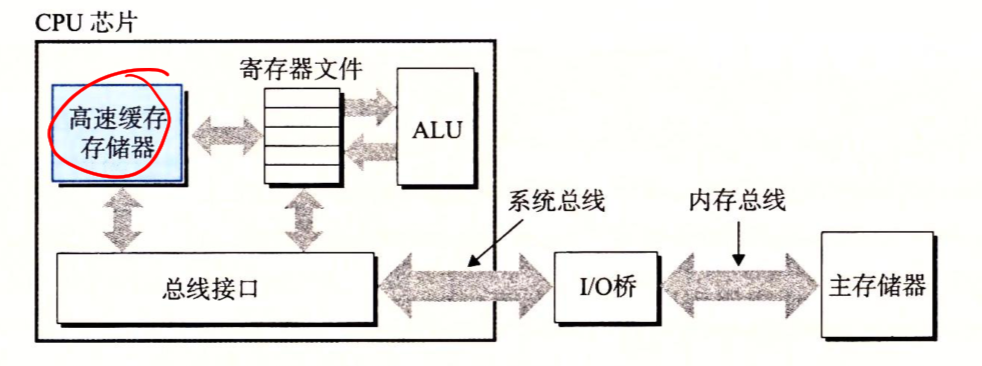
意识到高速缓存存储器存在的程序员能够利用高速缓存将程序的性能提高一个数量级。
存储器层次结构的示例:
操作系统管理硬件
当shell程序加载和运行hello程序时,以及hello程序输出自己的消息时,shell和hello程序都没有直接访问硬件,而是依靠操作系统来完成的。我们可以把操作系统看成应用程序和硬件之间插入的一层软件。
操作系统有两个大功能(1)防止硬件被失控的应用程序滥用;(2)向应用程序提供简单一致的机制来控制复杂而又通常不同的低级硬件设备。操作系统通过几个抽象的概念:进程、虚拟内存和文件来实现这两个功能。
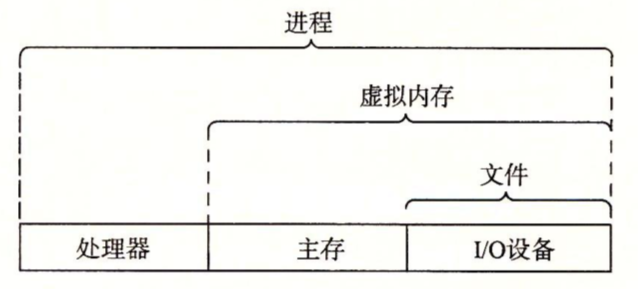
进程
进程就是正在运行的程序的一种抽象。在一个系统上可以同时运行多个进程,比如你可以后台挂刷课软件,然后打游戏。进程时线程的容器,进程是程序的实体,进程是计算机科学中最重要和最成功的概念之一。
传统的系统在一个时刻只能执行一个程序,而先进的多核处理器能够同时执行多个进程,这是通过处理器在进程间切换来实现的。操作系统实现这种交错执行的机制称为上下文切换。
一个进程到另一个进程的转换是由操作系统内核(Kernel)管理的。内核是操作系统代码常驻内存的部分。当应用程序需要操作系统的某些操作时,他就执行一条特殊的系统调用指令,将控制权递给内核。然后内核执行被请求的操作并返回应用程序。内核不是要给独立的进程,它是系统管理全部进程所用代码和数据结构的集合。
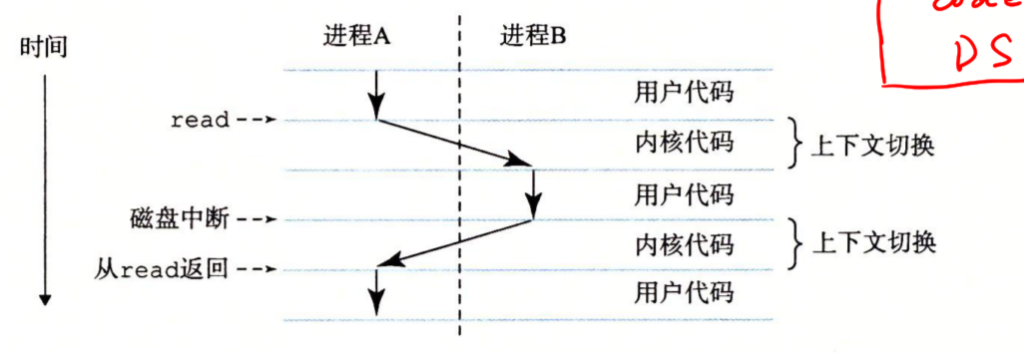
线程
一个进程实际上可以由多个称为线程的执行单元组成,所以说进程是线程的容器。每个线程都运行在进程的上下文中,并共享同样的代码和全局数据,因为多线程之间比多进程之间更容易共享数据,也因为线程一般来说都比进程高效,所以线程成为越来越重要的编程模型。(虽然我还没写过多线程的程序...)
虚拟内存
虚拟内存是一个抽象概念,模型图如下
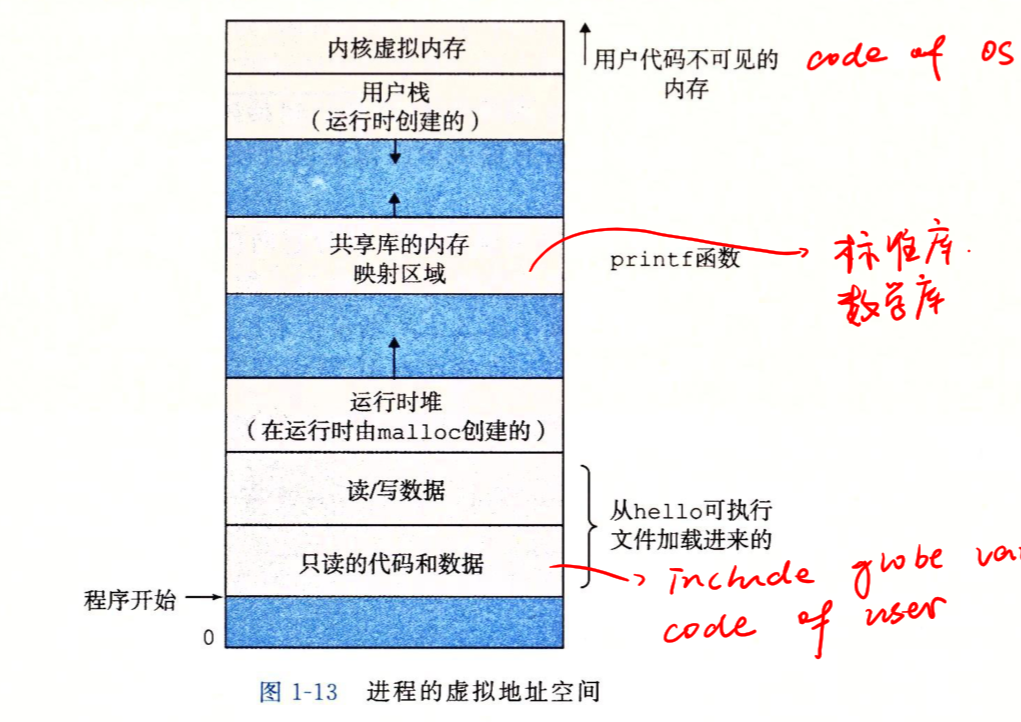
简单了解虚拟地址空间区是非常有用的
- 程序代码和数据:对所有进程来说,代码是从同一个固定地址开始,紧接着是全局变量相对应的数据位置。代码和数据区是直接按照可执行目标文件的内容初始化的。
- 堆:代码和数据区后紧随着的是运行时堆。代码和数据区在进程一开始运行就被指定了大小,而调用向malloc,free这样的c标准库函数时,堆可以在运行时动态扩展和收缩。堆的空间很大,所以在算法竞赛中一般大数组都开在全局变量,因为这是属于堆的空间。
- 栈:位于用户虚拟地址空间顶部的时用户栈,编译器用它来实现函数调用,用户栈在程序执行期间可以动态扩展和收缩。我们每调用一个函数,栈就会增长,从一个函数返回时,栈就会收缩。现在知道为啥递归容易爆栈了吧。
- 内核虚拟内存。地址空间顶部的区域是为内核保留的,不允许应用程序读写这个区域的内容或者直接调用内核代码定义的函数。相反,它们必须调用内核来执行这些操作。
系统之间的网络通信
从一个单独的系统来看,网络可视为一个I/O设备,当系统从内存复制一串字节到网络适配器时,数据流经过网络到达另一台机器,而不是比如说到达本低磁盘驱动器。相似地,系统可以读取从其他机器发送过来的数据,并把数据复制到自己的内存。
至此,系统漫游就结束了。系统不仅仅只是硬件,系统是硬件和系统软件互相交织的集合体,它们必须共同协作以达到运行应用程序的最终目的。
csapp:
链接:https://pan.baidu.com/s/1UvusJzFl4XQ4Mofj5z8eqA 提取码:e6rd 复制这段内容后打开百度网盘手机App,操作更方便哦
Comments NOTHING