

第一次写论文阅读的相关博客,并不是自己翻译论文,因为这个工作很多人做过了,主要是想记录一下论文的要点以及自己的理解。
MapReduce是Google的Jeffrey Dean于2004年发表的一篇论文,也是分布式技术的三驾马车之一(MapReduce,GFS,BigTable)

摘要
首先对MapReduce进行了定义:一种用于处理和生成大型数据集的编程模型的相关实现。这个编程模型抽象来说,包含map和reduce两个阶段,首先用户定义map函数来处理一系列的键值对(key: value),然后生成处理后的结果,这个结果称为中间键值对。第二阶段指定reduce函数来接收这个中间键值对,将含有相同key的键值对合并,并对value进行一些有关操作。现实中的很多任务都可以由这个编程风格表达。
Google设计的MapReduce系统是为了让那些没有并行计算和分布式编程经验的程序员使用这样的编程风格,MapReduce系统在运行时只关心:
- 分割输入数据
- 集群机器的调度
- 集群机器的故障处理
- 集群机器间的必要通信
在当时,一个标准的MapReduce系统就已经可以在数千台机器上处理TB级的数据了
1 简介
由于在2004年互联网刚刚兴起,谷歌作为搜索引擎的头部公司掌握着海量的数据,并且需要对这些数据进行数百种操作,比方说倒排索引,web文档的各种图表示等等,这些计算在概念上比较简单,但是由于数据太过庞大,并且为了能够在一个合理的时间内完成,所以需要依靠集群来完成。正是由于集群太过复杂,需要解决并行计算、分配数据以及故障处理的问题,使得简单的问题复杂化了。
所以为了隐藏这些内部处理的复杂细节,只对外开放接口,开发人员从Lisp和其他函数式编程语言中的map和reduce找到了灵感:我们意识到,大多数计算都涉及到对输入中的每个逻辑记录进行map操作,以便于计算出一个中间键值对的集合。然后,为了恰当的整合衍生数据,我们对共用相同键的所有值进行reduce操作。通过使用具备用户所指定的map和reduce操作的函数式模型,这使得我们能够轻松并行化大型计算,并且使用重新执行的结果作为容错的主要机制。
所以MapReduce的意义就在于提供了一个简单而强大的接口,使用这个接口可以实现分布式、高性能的大规模数据计算。
2 编程模型
编程模型包括Map和Reduce两个操作部分
- map操作:对于每条输入的记录,生成<key, value>形式的中间键值对 (intermediate key/value pairs)
- 对于map操作所生成的中间键值对,MapReduce系统首先将相同key的键值对合并,得到<key, [value1, value2, ...]>的形式,这个过程也叫做shuffle(洗牌),然后再送入reduce程序,传递的时候是通过一个迭代器来传的,这样可以避免因为list列表的数据量太大而无法存放在内存中。
- reduce操作:对value数组进行计算后得到最终的结果,这个结果的value通常只有0个或者1个(而不会是一个数组)。
2.1 wordcount案例
我们可以思考下这样一个场景,我们要从大量的文档中计算出每个单词的出现次数。用户将会编写出类似于下方伪代码的代码:
map(String key, String value):
// key: 文档的名字,我们通常不用管
// value: 文档的内容,也就是包含单词的内容
for each word w in value:
EmitIntermediate(w,"1"); // 生成中间结果
reduce(String key, Iterator values):
// key: 单词
// values: 由计数所组成的列表,也就是[1, 1, 1...]之类的
int result = 0;
for each v in values: //统计列表中有多少个1,也就是单词的出现次数
result += ParseInt(v);
Emit(AsString(result));wordcount流程图:
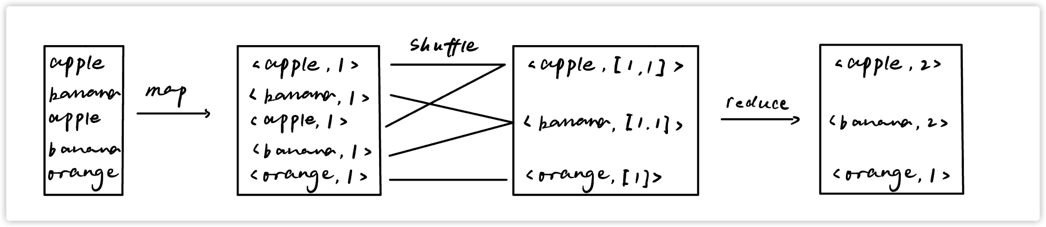
用户可以将代码链接到MapReduce库中(这个库是由C++实现的),框架将计算的数据准备妥当后调用,并且将执行结果写回到分布式系统中,也就是说,整个系统的执行流程只需要用户编写MR函数,而不需要感知其他的细节。
2.2 类型
伪代码中的类型输入输出都是String,但是实际上需要根据应用场景来调整,比方说map的输出类型要符合reduce的输入类型等等
2.3 更多案例
作者还提供了一些MapReduce模型表示的案例
- 分布式Grep:Map函数匹配某个规则的一行,reduce函数是一个恒等函数(f(x) = x,什么也不做)
- 计算URL访问频率:map函数处理网页请求日志提取,并生成<url, 1>,reduce函数则是将相同url的值都加起来
- 倒转网络链接图:map函数在源页面中找到所有的目标URL,并且输出<target, source>这样的键值对。reduce函数对于所有给定的键值对,根据target,构造出<target, list(source)]>这样的键值对
- 每台主机上的检索词向量(Term-Vector):检索词向量将一个或者一组文档中出现的最重要的词汇概括(summarizes)为 <word, frequency> 列表的形式。对于每个输入的文档,map函数输出一个<hostname, term vector>,其中hostname是从文档的URL中提取出来的,而对于每个给定的hostname,reduce函数接收每个文档的检索词向量。并且将这些检索词向量加起来,然后抛弃(thowing away)低频词汇,最后输出(emits)一个最终的<hostname, term vector>。
- 倒排索引:map函数解析每个文档,并且输出<word, document ID>这样的键值对序列,对于一个给定词汇的所有键值对,reduce函数首先会对文档ID进行排序,然后输出<word, list(document ID)>这样的键值对,所有输出键值对的集合可以形成一个简单的倒排索引,这样我们就能计算出每个单词在文档中的位置
- 分布式排序:map函数从每条记录中提取一个key,然后输出<key, record>这样的键值对,reduce函数对键值对不作任何修改,直接输出。这种计算任务依赖分区机制和排序属性。
3 实现
MapReduce根据不同的运行环境有着不用的实现,作者在本节介绍的是谷歌内部广泛使用的计算环境:通过以太网交换机链接,并且由商用PC(也就是说配置一般)组成的大型集群,环境如下:
- x86架构,Linux系统,双核CPU,2-4GB的内存
- 100Mbps或者1000Mbps的商用网络硬件
- 由成百上千台机子组成的集群,因此机子崩溃是常态
- 直接插在每台机子上的廉价IDE硬盘,内部通过一个分布式的文件系统来管理硬盘上的数据。这个文件系统使用多份拷贝的方式在不可靠的硬件上提供可用和可恢复的服务,保证数据不会丢失。
- 用户提交jobs到调度系统,每个job包括一系列的tasks,调度系统将这些tasks调度到集群中可用的机器上运行
3.1 执行概述(重要)
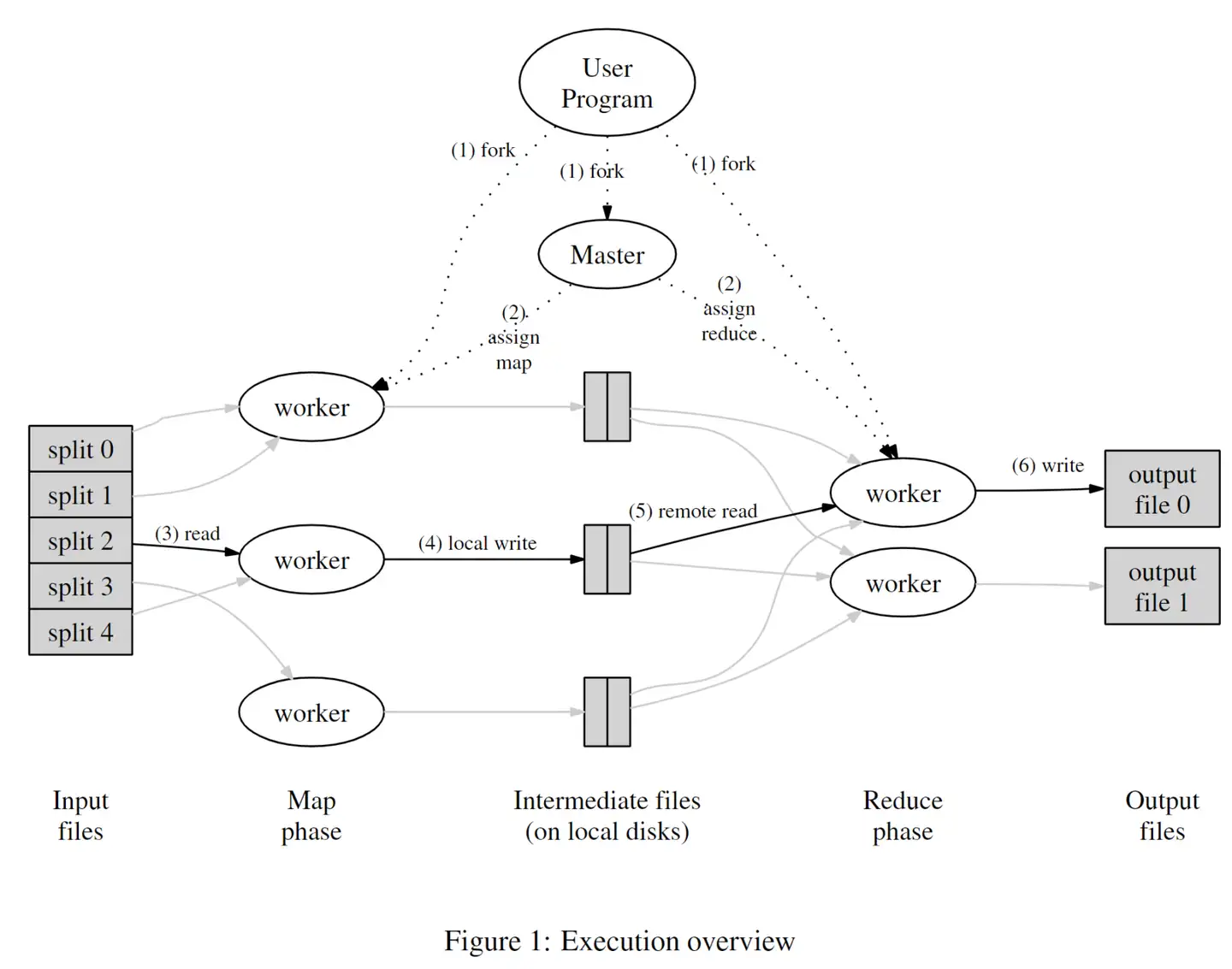
上图展示了MapReduce数据处理的流程图,当用户程序调用MapReduce函数时会发生一系列的动作:(序号一一对应)
(1) 最上层的用户程序首先将数据分成M片,每片通常在$16 \sim 64 MB$之间,接着会使用fork函数创建出多个程序副本,也就是上图中的一系列worker和一个特殊的Master,woker和Master就对应集群中的一个个主机。
(2) Master节点会为集群中空闲的主机来分配一个map任务或者一个reduce任务
(3) worker节点从数据片段中读取键值对,并且传入map函数进行处理,map函数生成的中间结果首先缓存在内存中。
(4) 每隔一段时间,worker就会将内存中缓存的中间结果写到本地的磁盘上,并且通过分区函数分到R个区域内,这些位置会传回给Master节点,之后由Master将这些位置告诉执行reduce的worker
(5) 执行reduce的worker收到Master的命令后会通过RPC (远程过程调用) 读取对应的位置,读取完毕后会根据中间结果的key进行排序,以便具有相同key的键值对能够聚合到一起,如果数据量太大内存放不下,那么就要考虑使用外部排序。
(6) reduce worker 将数据集合传入用户提供的reduce函数中,执行完成后会将输出结果存储到该分区对应的输出文件。
(7) 所有map和reduce完成后,master会唤醒用户程序。此时,用户程序会结束对MapReduce的调用
每次Mapreduce分片的M和R都比worker的数量要大得多,这样可以更好的实现负载均衡
3.2 Master的数据结构
Master中保存了每个Map和Reduce(这里大些是特指执行map和reduce的worker)任务的状态(闲置、正在运行、执行完成),以及非空闲的任务和worker机器的ID
3.3 容错(Fault Tolerance)
因为机器数量太多,所以容错对MapReduce来说是至关重要的
worker故障
Master会周期性的ping一下每个worker,如果在一定时间内无法接收到该worker的响应,那么就会将该worker标记为failed,并且指派到该worker上所有的map和reduce任务的状态都会设置为初始的idle状态,并且交给其他空闲worker来执行。在一个failed的worker上,所有的map都会重新执行,包括已经执行过的,因为输出结果在该机器的硬盘中,是无法访问的,而已经执行过的reduce操作则不必重新执行,因为其输出结果已经保存到了全局文件系统中。
当执行map的worker A失效,而将任务转移到worker B上时,Master会通知所有的reduce worker,那些应该从worker A中读取数据的reduce worker会从worker B中读取数据。
Master故障
由于整个节点中只有一个Master,所以Master失效的场景是非常少的,最简单的做法是直接重新开始整个作业,还有一个解决方法是将Master的数据结构周期性的保存到硬盘中,设置checkpoint,这样当Master挂掉时可以重新从上一个checkpoint处继续执行。
3.4 本地化(Locality)
由于网络带宽在那个时代是相当稀缺的资源,worker、Master之间的通信就得消耗一部分带宽,若数据传输也依靠网络则会严重影响系统的执行时间,因此设计者通过将输入数据从本地硬盘读取来减少对网络的依赖。比方说,GFS(Google File System)将输入文件分块后分散在不同的机器上,并保存多份拷贝(一般是三份),当Master调度worker执行任务时会考虑文件的位置信息,并且尽可能在该机器上执行,如果任务失败,则会考虑从临近的主机中读取该数据的拷贝,因此大部分的输入数据会在本地进行,不会消耗网路带宽。
3.5 任务粒度(Task Granularity)
任务的粒度也就是考虑分片时的M和R,其中M是输入数据的分片大小,也就是map任务的数量,R是输出数据的分区个数,也就是reduce的任务个数,一般来说R的大小由用户指定,因为R也是MapReduce执行完成后的输出文件个数,有时候也指定M,因为要可以让每个分片大小在$16 \sim 64MB$之间。M和R一般是远大于worker的数量的,一方面是可以提高动态负载均衡的能力,另一方面是worker挂掉后可以快速恢复。
当然M和R的大小也需要作出必要的限制,Master必须要进行$O(M + R)$次调度,并且在内存中保存着$O(M\times R)$个状态。
3.6 备份任务(Backup Tasks)
影响MapReduce系统执行的一个常见因素就是落伍者("straggler")的出现,也就是说系统需要花一段很长的时间来执行最后的几个任务,落伍者出现的原因有很多,比如某个机器上的硬盘出了问题之类的导致读写速度变慢等等。解决的方法是在MapReduce接近执行完成时,会调度一个备用任务来执行剩下正在执行中的任务,无论是主任务还是备用任务完成,都将该任务标记为完成。
该策略只需要花费少量的计算资源,就可以节约大量的计算时间,很厉害。
Mapreduce的主体就是上面的内容了,还有一些使用技巧和性能测试就不说了。
Comments 4 条评论
#私密# xd你好,我去年看你二战暨大,最后怎么样了?好像去年我建议你跳车科软来着
@11119045415 我没跳车,科软一堆神仙打架,我还是算了hhh,估计今年差不多能进个复试吧
@vsbf okk,出分记得在发一篇hh,这是想走分布式?
@11119045415 哈哈哈可以的,目前对分布式比较感兴趣一些,就先学着玩儿,具体以后啥方向估计还得看导师吧(如果能上岸)