

简单介绍
Scrapy是Python的一个爬虫框架,包含以下组件:
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
此组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
当页面被爬虫解析所需的数据存入Item后,将被发送到项目管道(Pipeline),并经过几个特定的次序处理数据,最后存入本地文件或存入数据库。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
通过设置下载器中间件可以实现爬虫自动更换user-agent、IP等功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流(Data flow)
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中的start_urls列表中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
快速上手
首先是在一个虚拟环境中pip install scrapy,windows下安装貌似会出一些问题,可以百度解决,mac和linux安装没有遇到过问题。
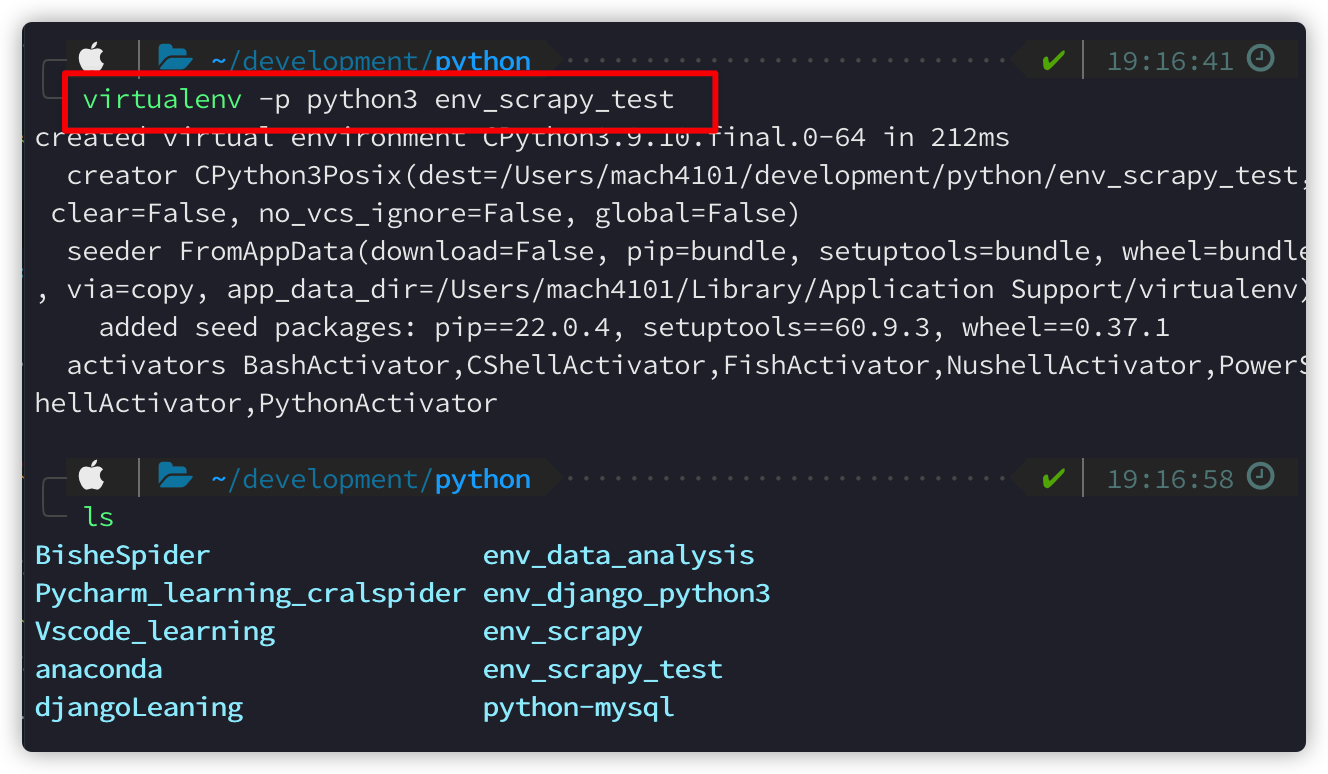

然后cd进入要存放项目的目录,运行scrapy startproject NAME来创建一个scrapy项目:
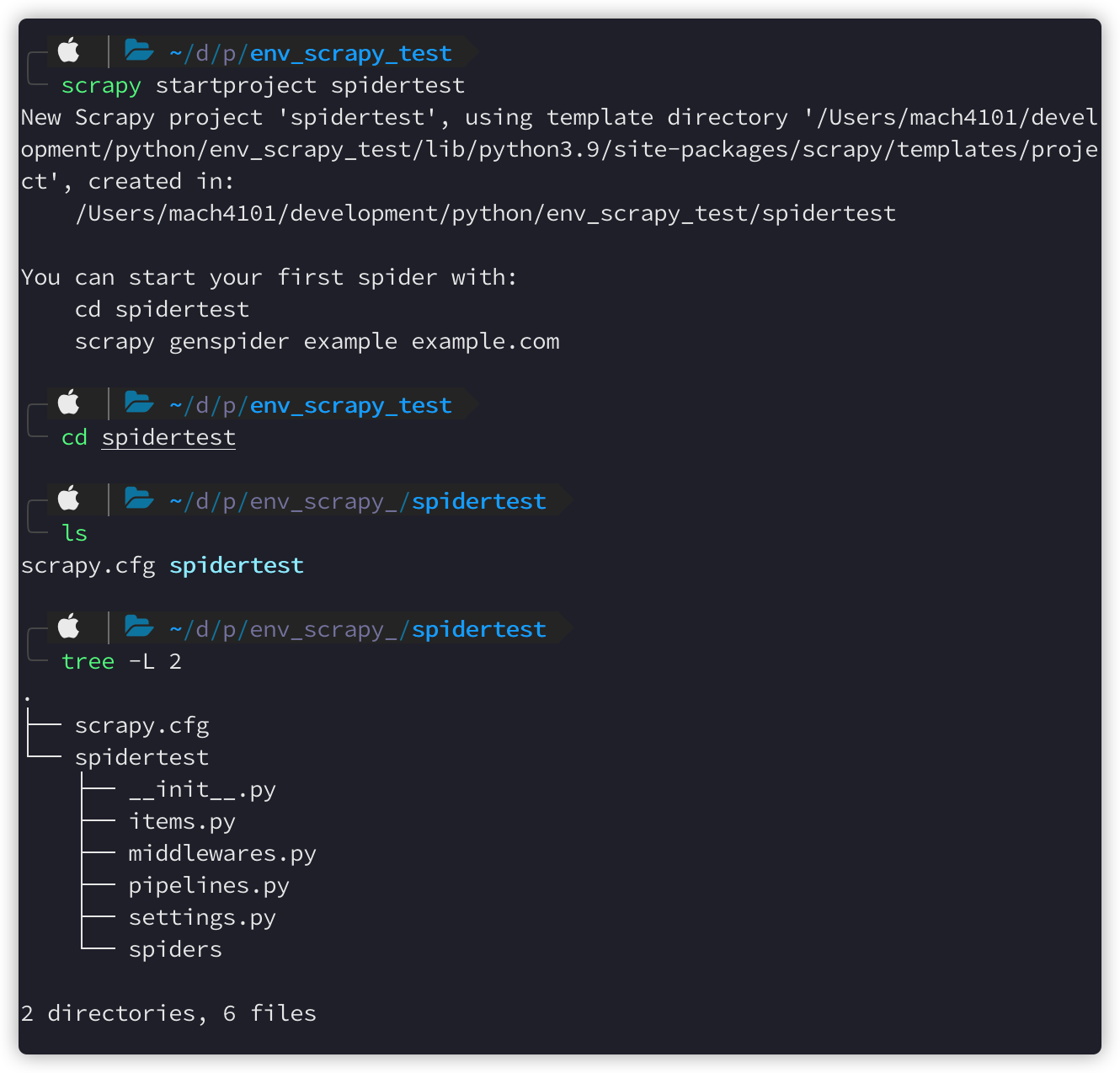
项目的目录如上图所示
- scrapy.cfg: 项目的配置文件。
- spidertest/: 该项目的python模块。之后可以在此加入代码。
- spidertest/items.py: 项目中的item文件,用于保存字段
- spidertest/pipelines.py: 项目中的pipelines文件,用于处理数据
- spidertest/settings.py: 项目的设置文件,用于配制该scrapy项目
- spidertest/spiders/: 放置spider代码的目录。
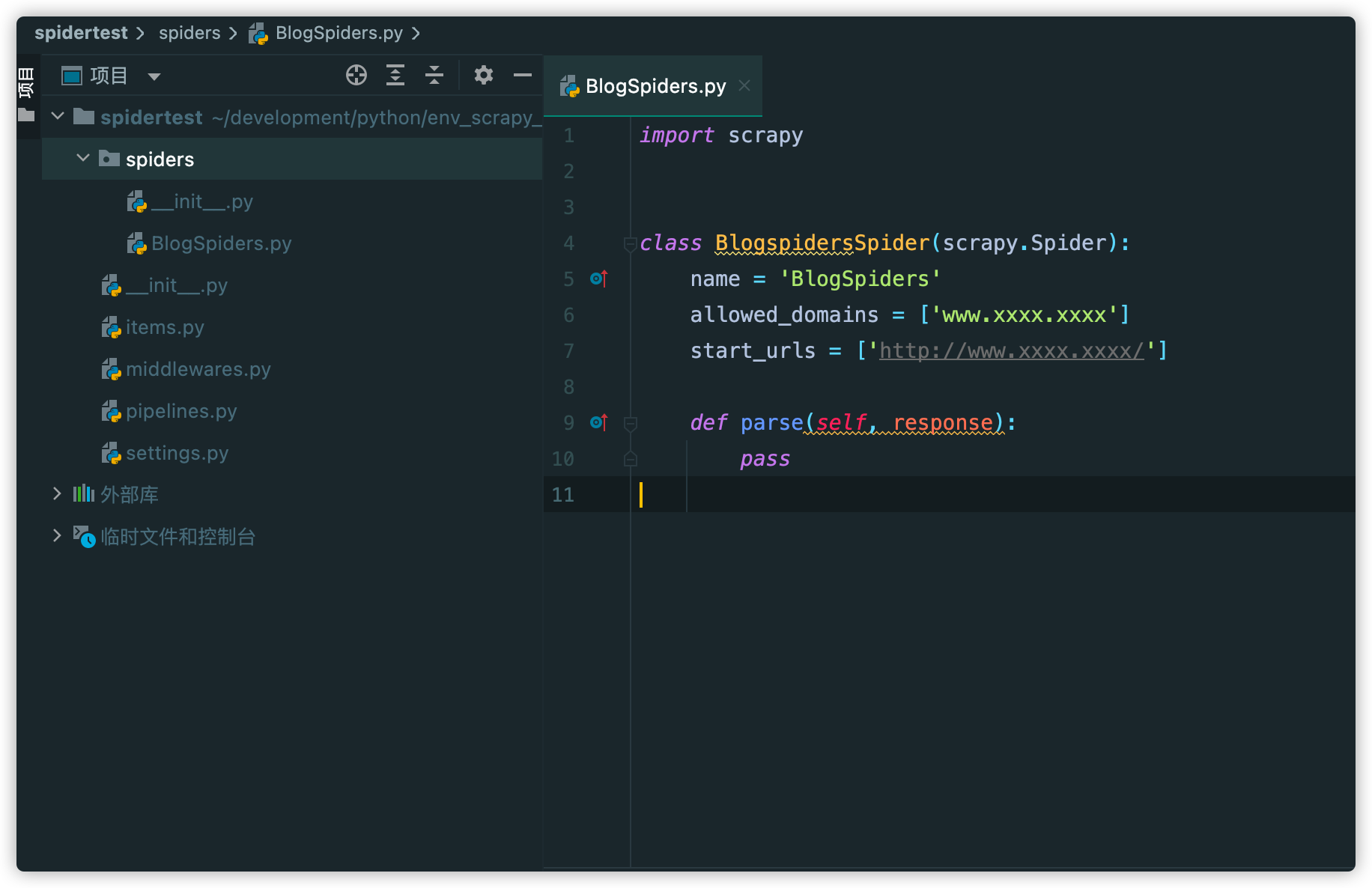
然后我们来创建第一个spider文件:scrapy genspider BlogSpiders https://www.xxxx.xxxx,其中BlogSpiders是该spider的名字,后面是要爬取的域名。运行完成后,会发现我们的spiders文件夹下面自动生成了一个BlogSpiders:
自定义一个Item容器
我们从网页上获取一些数据后,肯定是需要讲这些数据暂存起来,以往我们的方式可能是声明一个字典,然后将数据保存到字典中,如果需要抓取很多条数据的话,我们就会再声明一个列表,将这些字典存到列表中。但是在Scrapy中,有一个叫Item的东西,类似字典,但是比字典强大,具体的使用如下:
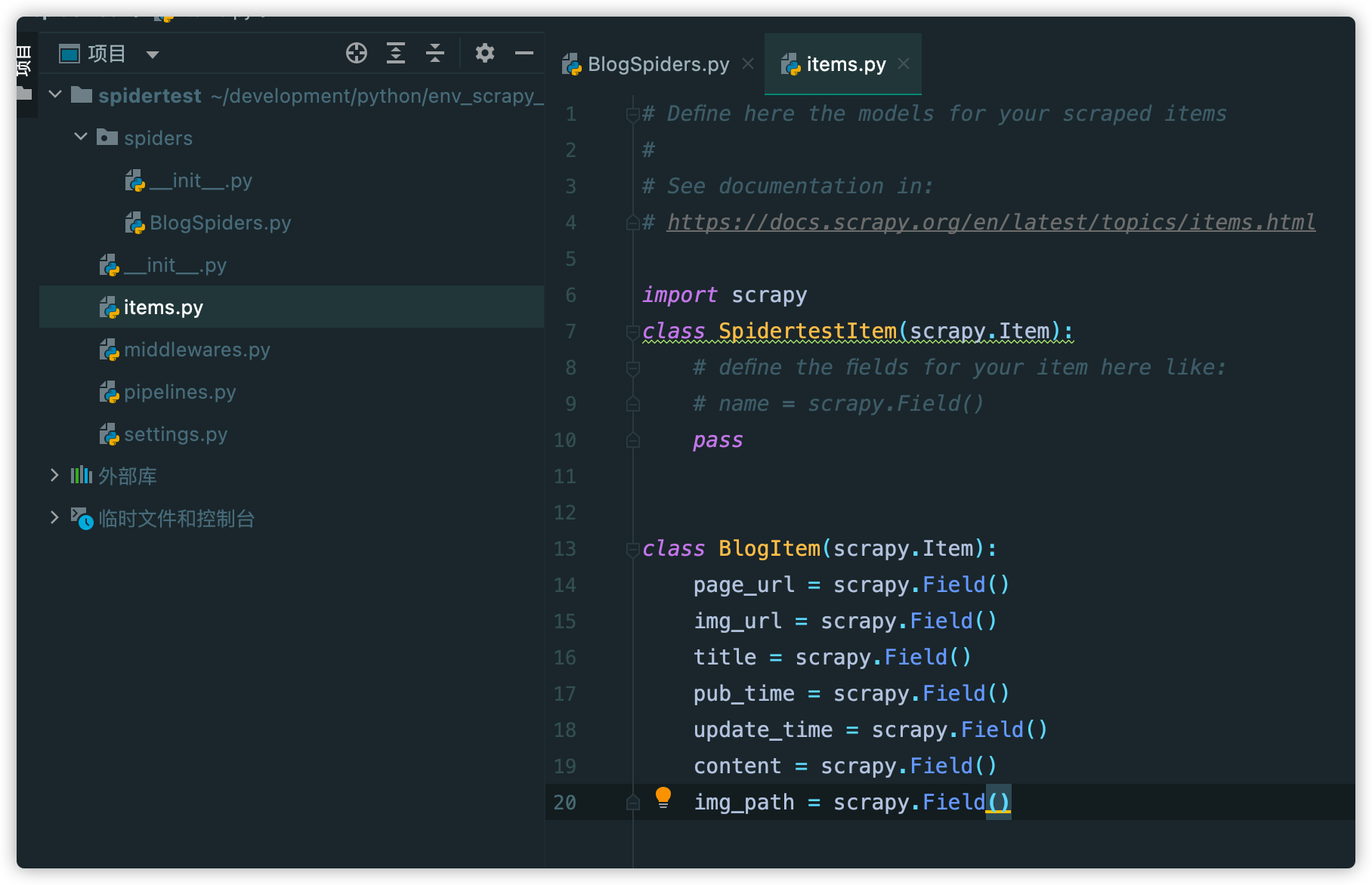
在Item这个文件中,我们可以自定义一个用于存放博客信息的BlogItem类,它继承自scrapy.Item,然后下面就是自定的字段,比如我们要爬取某个博客网站,那么肯定就需要爬该文章的链接:page_url,还有封面图的url:img_url等信息
编写解析器
就如同我们使用普通的requests需要解析网页一样,scrapy中在parse处主要编写用于解析网页的代码,一般解析工具可以使用xpath或者css选择器,我比较擅长使用xpath,所以就用xpath,具体的xpath语法这里不详细说,bilibili上面有很多教程。比如我需要爬取某个blog,解析写法如下:
def parse(self, response):
page_nodes = response.xpath("//div[@class='recent-post-item']/div")
for page_node in page_nodes:
blogItem = BlogItem()
page_url = page_node.xpath(".//a/@href").extract_first("")
img_url = page_node.xpath('.//img[@chenlass="post_bg"]/@src').extract_first("")
page_url = parse.urljoin(response.url, page_url)
img_url = parse.urljoin(response.url, img_url)
blogItem['page_url'] = page_url
blogItem['img_url'] = [img_url] # 需要下载的图片key,所对应的value应该是一个列表
yield Request(page_url, meta={'blogItem': blogItem}, callback=self.parse_detail)
def parse_detail(self, response):
title = response.xpath('//*[@id="post-info"]/h1/text()').extract_first("")
pub_time = response.xpath('//*[@id="post-meta"]/div[1]/span/time[1]/text()').extract_first("")
update_time = response.xpath('//*[@id="post-meta"]/div[1]/span/time[2]/text()').extract_first("")
content = response.xpath('//*[@id="article-container"]').extract_first("")
blogItem = response.meta.get('blogItem',"")
blogItem['title'] = title
blogItem['pub_time'] = pub_time
blogItem['update_time'] = update_time
blogItem['content'] = content
yield blogItemparse函数名称是提前固定好的,所以我们只用在里面编写代码即可,它包含response参数,这个response就是scrapy帮我们request的时候所相应的对象,你可以直接print(response.text)来查看该网页的源代码,也可以直接在response上使用xpath语法,就如我上面所写。
page_nodes这个元素包含文章的部分信息,比如博客的标题、链接、封面图之类的,我们遍历page_nodes,使用xpath提取这些信息,然后将数据保存在BlogItem中。保存好该Item后,我们可以对其进行下一步解析,因为我们还需要博客的发布时间、文章的内容等等,所以可以yield一个请求出去,该请求包含三个参数,第一个参数是下一步要访问的url,第二个参数是meta,用于传递数据,第三个参数是一个回调函数,下一步将这个函数来处理url,在这里就是parse_detail这个函数。
在parse_url中,我们主要想提取这篇文章的具体信息,比如内容之类的,也将它存储到Item中之后,yield出去。关于yield这个东西,在scrapy中只允许yield两种数据,第一种是Ruquest,也就是上面那个函数我们所yield的东西,它会跳转到callback函数进行进一步的处理。第二种是Item数据,也就是我们这个地方所yield的blogItem,它会跳转到piplines中进行处理,那么下一步我们就来写piplines中的内容。
编写piplines
piplines就是对item对象进行处理的模块,我们可以将其保存为json文件,也可以下载文件,也可以将其保存到数据库中,这里就以保存到mysql中为例,这块的框架可以复制粘贴,只需要更改do_insert操作即可
# 异步更新操作
class MysqlTwistedPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_settings(cls, settings): # 固定写法,可以使用setting中的值
"""
数据库建立链接
:param settings: 配置参数
:return: 实例化参数
"""
adbparams = dict(
host = settings['MYSQL_HOST'],
port = settings['MYSQL_PORT'],
db = settings['MYSQL_DBNAME'],
user = settings['MYSQL_USER'],
password = settings['MYSQL_PASSWORD'],
cursorclass=pymysql.cursors.DictCursor
)
# 数据库连接池,使用pymysql连接
dbpool = adbapi.ConnectionPool('pymysql', **adbparams)
return cls(dbpool)
def process_item(self, item, spider):
"""
使用twisted将mysql插入变成异步执行,通过连接池执行具体的sql操作,返回一个对象
:param item:
:param spider:
:return:
"""
query = self.dbpool.runInteraction(self.do_insert, item)
# 添加异常处理
query.addErrback(self.handle_error, item, spider)
def do_insert(self, cursor, item): # 灵活
insert_sql = """
insert into blog (page_url, page_url_md5, img_url, title, pub_time, update_time, content, img_path)
values (%s, %s, %s, %s, %s, %s, %s, %s) ON DUPLICATE KEY UPDATE page_url = VALUES(page_url)
"""
params = list()
params.append(item.get('page_url', ""))
params.append(item.get('page_url_md5', ""))
img_str = ",".join(item.get('img_url', []))
params.append(img_str)
params.append(item.get('title', ""))
params.append(item.get('pub_time', "1979-01-01"))
params.append(item.get('update_time', "1979-01-01"))
params.append(item.get('content', ""))
params.append(item.get('img_path', ""))
cursor.execute(insert_sql, tuple(params))
def handle_error(self, failure, item, spider):
if failure:
print(failure)编写settings:
在settings中,有几处是需要更改的
ROBOTSTXT_OBEY = False,如果是True的话就改成False,也就是不遵守爬虫规定......
ITEM_PIPELINES = {
'spidertest.pipelines.SpidertestPipeline': 300,
'spidertest.pipelines.MysqlTwistedPipeline': 1
}然后添加我们刚刚写的MysqlTwistedPipline,后面的数字的意思是执行的顺序,也就是一个item被yield出来之后,先调用Mysqlxx这个,然后再调用默认的pipline
加入数据库的配置信息:
MYSQL_HOST = "127.0.0.1"
MYSQL_PORT = 3306
MYSQL_DBNAME = "article_spider"
MYSQL_USER = "root"
MYSQL_PASSWORD = "your password here"运行
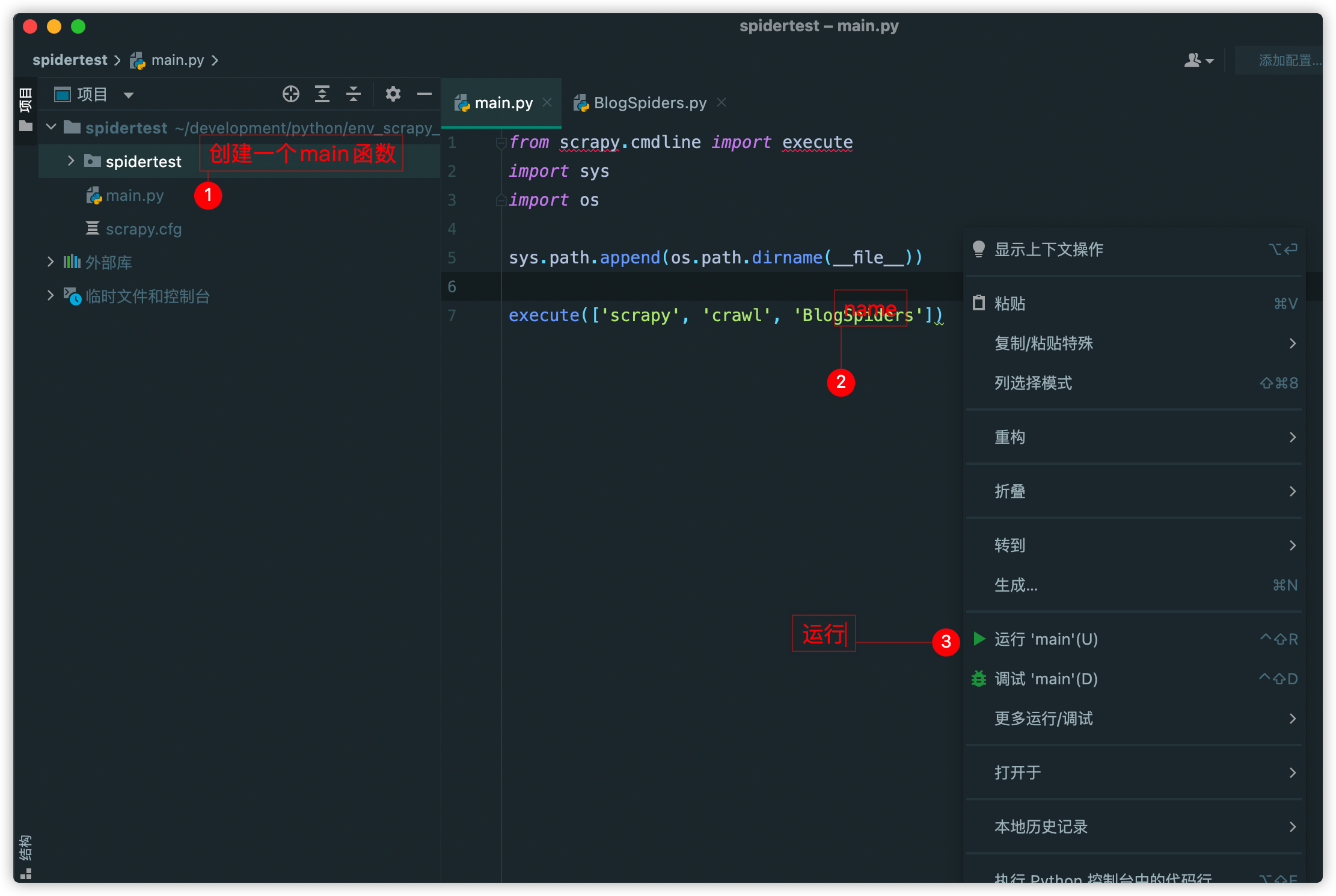
为了方便调试和运行方便,我们可以在spidertest文件夹下面创建一个main函数来执行,方便调试
总结
这篇博客不算是实战教程,只是把该项目中的一些关键点说了一下,并不详细,相当于我自己做的一个笔记,也感谢您阅读到这里,谢谢。
Comments NOTHING