

啥是主成分?
主成分分析(Principal Component Analysis,PCA),主成分分析是一种降维算法,能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始变量的大部分信息。一般来说,当我们研究的问题涉及到很多的变量,且多个变量之间存在很强的相关行时,我们可以考虑使用主成分分析对数据进行简化。
降维有啥用?
降维是将高维度的数据(指标太多)保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。
在实际的生产应用中,降维在一定的信息损失范围内,可以为我们节省大量的时间和成本,降维也成为应用非常广泛的数据预处理方法。
好处:
- 使得数据集更加容易使用
- 降低算法的计算开销
- 去除噪声
- 使得结果容易理解
主成分的思想
假设有\(n\)个样本,\(p\)个指标,则可构成大小为\(n*p\)的样本矩阵\(x\):
$$
x=\left[ \begin{matrix}
x_{11}& x_{12}& \cdots& x_{1p}\\
x_{21}& x_{22}& \cdots& x_{2p}\\
\vdots& \vdots& \ddots& \vdots\\
x_{n1}& x_{n2}& \cdots& x_{np}\\
\end{matrix} \right] =\left( x_1,x_2,\cdots ,x_p \right)
$$
假设我们想找到新的一组变量\(z_1,z_2,\cdots ,z_m\left( m\leqslant p \right)\),且他们满足:
$$
\begin{cases}
z_1=l_{11}x_1+l_{12}x_2+\cdots +l_{1p}x_p\\
z_1=l_{21}x_1+l_{22}x_2+\cdots +l_{2p}x_p\\
\,\, \vdots\\
z_m=l_{m1}x_1+l_{m2}x_2+\cdots +l_{mp}x_p\\
\end{cases}
$$
其中,系数\(l_{ij}\)确定的原则:
- \(z_i\)与\(z_j\left( i\ne j;i,j=1,2,\cdots ,m \right)\)相互无关
- \(z_1\)是\(x_1,x_2,\cdots ,x_p\)的一切线性组合中方差最大者
- \(z_2\)是与\(z_1\) 不相关 \(x_1,x_2,\cdots ,x_p\)的所有线性组合中方差最大者
- 依此类推,\(z_m\)是与\(z_1,z_2,\cdots ,z_{m-1}\)不相关的\(x_1,x_2,\cdots ,x_p\)的所有线性组合中方差最大者,为什么是方差,可以点击这里
- 新变量指标\(z_1,z_2,\cdots ,z_m\)分别称为原变量指标\(x_1,x_2,\cdots ,x_p\)的第一,第二……第m主成分
关于严格的数学证明,可以看看这个
主成分计算步骤
假设有\(n\)个样本,\(p\)个指标,则可以构成\(n*p\)的样本矩阵\(x\)
$$
x=\left[ \begin{matrix}
x_{11}& x_{12}& \cdots& x_{1p}\\
x_{21}& x_{22}& \cdots& x_{2p}\\
\vdots& \vdots& \ddots& \vdots\\
x_{n1}& x_{n2}& \cdots& x_{np}\\
\end{matrix} \right] =\left( x_1,x_2,\cdots ,x_p \right)
$$
step1:我们首先对其进行标准化
按列计算均值:\(\overline{x_j}=\frac{1}{n}\sum_{i=1}^n{x_{ij}}\)和标准差\(S_j=\sqrt{\frac{\sum_{i=1}^n{\left( x_{ij}-\overline{x_j} \right)}}{n-1}}\)
使用均值和方差标准化数据\(X_{ij}=\frac{x_{ij}-\overline{x_j}}{S_j}\),原始矩阵经过标准化之后:
$$
X=\left[ \begin{matrix}
X_{11}& X_{12}& \cdots& X_{1p}\\
X_{21}& X_{22}& \cdots& X_{2p}\\
\vdots& \vdots& \ddots& \vdots\\
X_{n1}& X_{n2}& \cdots& X_{np}\\
\end{matrix} \right] =\left( X_1,X_2,\cdots ,X_p \right)
$$
step2:计算标准化样本的协方差:
$$
R=\left[ \begin{matrix}
r_{11}& r_{12}& \cdots& r_{1p}\\
r_{21}& r_{22}& \cdots& r_{2p}\\
\vdots& \vdots& \ddots& \vdots\\
r_{n1}& r_{n2}& \cdots& r_{np}\\
\end{matrix} \right]
$$
其中\(r_{ij}=\frac{1}{n-1}\sum_{k=1}^n{\left( X_{ki}-\overline{X_i} \right) \left( X_{kj}-\overline{X_j} \right) =\frac{1}{n-1}\sum_{k=1}^n{X_{ki}X_{kj}}}\)
前两步也可以合并,直接计算x矩阵的样本相关系数矩阵:
$$R=\frac{\sum_{k=1}^n{\left( x_{ki}-\overline{x_i} \right) \left( x_{kj}-\overline{x_j} \right)}}{\sqrt{\sum_{k=1}^n{\left( x_{ki}-\overline{x_i} \right) ^2\left( x_{kj}-\overline{x_j} \right) ^2}}}$$
step3:计算R的特征值和特征向量
特征值:\(\lambda _1\ge \lambda _2\ge \lambda _3\ge \cdots \ge \lambda _p\ge 0\)(R是半正定矩阵,且\(tr\left( R \right) =\sum_{k=1}^p{\lambda _k=p}\))
特征向量:
$$
a_1=\left[ \begin{array}{c}
a_{11}\\
a_{21}\\
\vdots\\
a_{p1}\\
\end{array} \right] , a2=\left[ \begin{array}{c}
a_{12}\\
a_{22}\\
\vdots\\
a_{p2}\\
\end{array} \right] , \cdots ,a_n=\left[ \begin{array}{c}
a_{1n}\\
a_{2n}\\
\vdots\\
a_{pn}\\
\end{array} \right]
$$
step4:计算主成分贡献率以及累计贡献率
贡献率:
$$
\frac{\lambda_i}{\sum_{k=1}^p{\lambda _k}}\left( i=1,2,\cdots ,p \right)
$$
累计贡献率:
$$\frac{\sum_{k=1}^i{\lambda_k}}{\sum_{k=1}^p{\lambda _k}}\left( i=1,2,\cdots ,p \right)$$
step5:写出主成分:
一般取累计贡献率超过80%的特征值所对应的第一、第二、第m个主成分。第\(i\)个主成分:\(F_i=a_{1i}X_1+a_{2i}X_2+\cdots +a_{pi}X_p\)
step6:根据系数分析主成分代表的意义:
对于某个主成分而言,指标前面的系数越大,代表该指标对于该主成分的影响越大。
step7:利用主成分的结果进行后续分析
- 主成分可以用于聚类分析
- 主成分可以用于回归分析
- 主成分不可用于评价类模型,这个很多人容易搞错,包括我们学校培训的老师
一些说明:
在主成分分析中,我们首先应保证所提取的前几个主成分的累计贡献率达到一个较高的水平,其次对这些被提取的主成分必须都能够给出符合实际背景和意义的解释。主成分的解释其含义一般多少带有点模糊性,不像原始变量的含义那么清晰,这是变量降维过程中不得不付出的代价。
如果原始变量的相关性较强,则前面少数几个主成分的累计贡献率通常都能达到一个较高的水平,也就是说,此时的累计贡献率通常较易得到满足
主成分分析中的困难之处在于要能够给出主成分的较好的解释,所提取的主成分中如果有一个主成分解释不了,整个主成分分析也就失败了。
主成分分析是变量降维的一种重要、常用的方法,简单地说,该方法要应用成功,一是靠原始变量的合理选取,二是靠“运气”
--《应用多元统计分析》王学民
例题:
在制定服装标准的过程中,对128名成年男子的身材进行了测量,每人测得的 指标中含有这样六项:身高(x1)、坐高(x2)、胸围(x3)、手臂长(x4)、 肋围(x5)和腰围(x6)。所得样本相关系数矩阵(对称矩阵)列于下表:
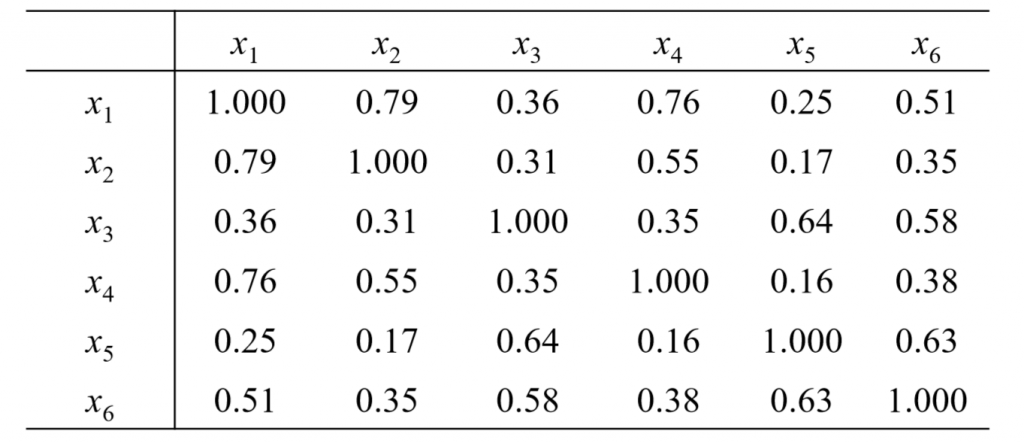
首先计算关键变量:
经过计算,相关系数矩阵的特征值、相应的特征向量以及贡献率列于下表:
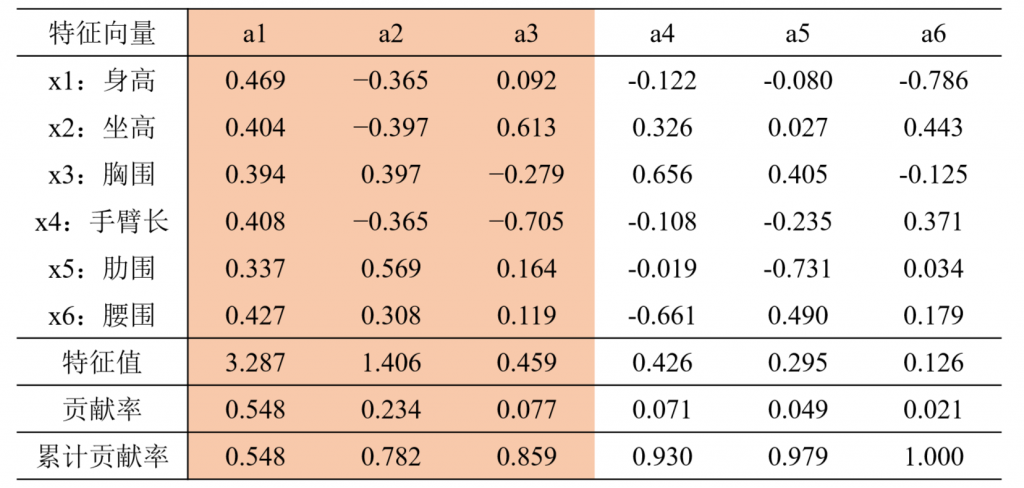
从表中可以看到前三个主成分的累计贡献率达85.9%,因此可以考虑 只取前面三个主成分,它们能够很好地概括原始变量。
$$
F_1=0.469X_1+0.404X_2+0.394X_3+0.408X_4+0.337X_5+0.427X_6
\\
F_2=-0.365X_1-0.397X_2+0.397X_3-0.365X_4+0.569X_5+0.308X_6
\\
F_3=0.092X_1+0.613X_2-0.279X_3-0.705X_4+0.164X_5+0.119X_6
\\
$$
\(X_i\)均是标准化之后的指标,\(x_i\):身高、胸围、手臂长、肋围长和腰围
第一主成分\(F_1\)对所有原始变量都有近似相等的正载荷,故称第一主成分为(身材)大小成分
第二主成分\(F_2\)在\(X_3,X_5,X_6\)上有中等程度的正载荷,而在\(X_1,X_2,X_4\)上有中等程度的负载荷,故称第二主成分为形状成分(或胖瘦成分)
第三主成分\(F_3\)在\(X_2\)上有大的正载荷,在\(X_4\)上有大的负载荷,而在其余变量上的载荷都比较小,可称第三主成分为臂长成分
注:由于第三主成分的贡献率不高,切实际意义也不太重要,因此我们可以只考虑取两个主成分来进行分析
最后附上matlab代码:
[n,p] = size(x); % n是样本个数,p是指标个数
%% 第一步:对数据x标准化为X
X=zscore(x); % matlab内置的标准化函数(x-mean(x))/std(x)
%% 第二步:计算样本协方差矩阵
R = cov(X);
%% 注意:以上两步可合并为下面一步:直接计算样本相关系数矩阵
R = corrcoef(x);
disp('样本相关系数矩阵为:')
disp(R)
%% 第三步:计算R的特征值和特征向量
[V,D] = eig(R); % V 特征向量矩阵 D 特征值构成的对角矩阵
%% 第四步:计算主成分贡献率和累计贡献率
lambda = diag(D); % diag函数用于得到一个矩阵的主对角线元素值(返回的是列向量)
lambda = lambda(end:-1:1); % 因为lambda向量是从小大到排序的,我们将其调个头
contribution_rate = lambda / sum(lambda); % 计算贡献率
cum_contribution_rate = cumsum(lambda)/ sum(lambda); % 计算累计贡献率 cumsum是求累加值的函数
disp('特征值为:')
disp(lambda') % 转置为行向量,方便展示
disp('贡献率为:')
disp(contribution_rate')
disp('累计贡献率为:')
disp(cum_contribution_rate')
disp('与特征值对应的特征向量矩阵为:')
% 注意:这里的特征向量要和特征值一一对应,之前特征值相当于颠倒过来了,因此特征向量的各列需要颠倒过来
% rot90函数可以使一个矩阵逆时针旋转90度,然后再转置,就可以实现将矩阵的列颠倒的效果
V=rot90(V)';
disp(V)
%% 计算我们所需要的主成分的值
m =input('请输入需要保存的主成分的个数: ');
F = zeros(n,m); %初始化保存主成分的矩阵(每一列是一个主成分)
for i = 1:m
ai = V(:,i)'; % 将第i个特征向量取出,并转置为行向量
Ai = repmat(ai,n,1); % 将这个行向量重复n次,构成一个n*p的矩阵
F(:, i) = sum(Ai .* X, 2); % 注意,对标准化的数据求了权重后要计算每一行的和
end
Comments NOTHING