

urllib库是python中的网络请求库,模拟浏览器行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据,urllib包含四个子模块:
- url.request 负责请求
- urllib.error 异常处理模块
- urllib.parse url负责解析
- urllib.robotparser负责robots.txt文件的解析
其中urllib.request 模块提供了最基本的构造 HTTP (或其他协议如 FTP)请求的方法,利用它可以模拟浏览器的一个请求发起过程。利用不同的协议去获取 URL 信息。它的某些接口能够处理基础认证 ( Basic Authenticaton) 、redirections (HTTP 重定向)、 Cookies (浏览器 Cookies)等情况。而这些接口是由 handlers 和 openers 对象提供的。
urlopen函数
在python3的urllib库中,所有何网络请求相关的方法,都被集到urllib.request模块下面了,urlopen函数的基本使用:
request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- 其中url为要访问的目标网址,
- data:Post 提交的数据, 默认为 None ,发送一个GET请求到指定的页面,当 data 不为 None 时, urlopen() 提交方式为 Post
- timeout:设置网站访问超时时间
urlopen 返回一个类文件对象,并提供了如下方法:
- read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
- info():返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息;可以通过Quick Reference to Http Headers查看 Http Header 列表。
- getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到
- geturl():返回获取页面的真实 URL。在 urlopen(或 opener 对象)可能带一个重定向时,此方法很有帮助。获取的页面 URL 不一定跟真实请求的 URL 相同。
from urllib import request
resp = request.urlopen('http://www.baidu.com')
print(resp.read())
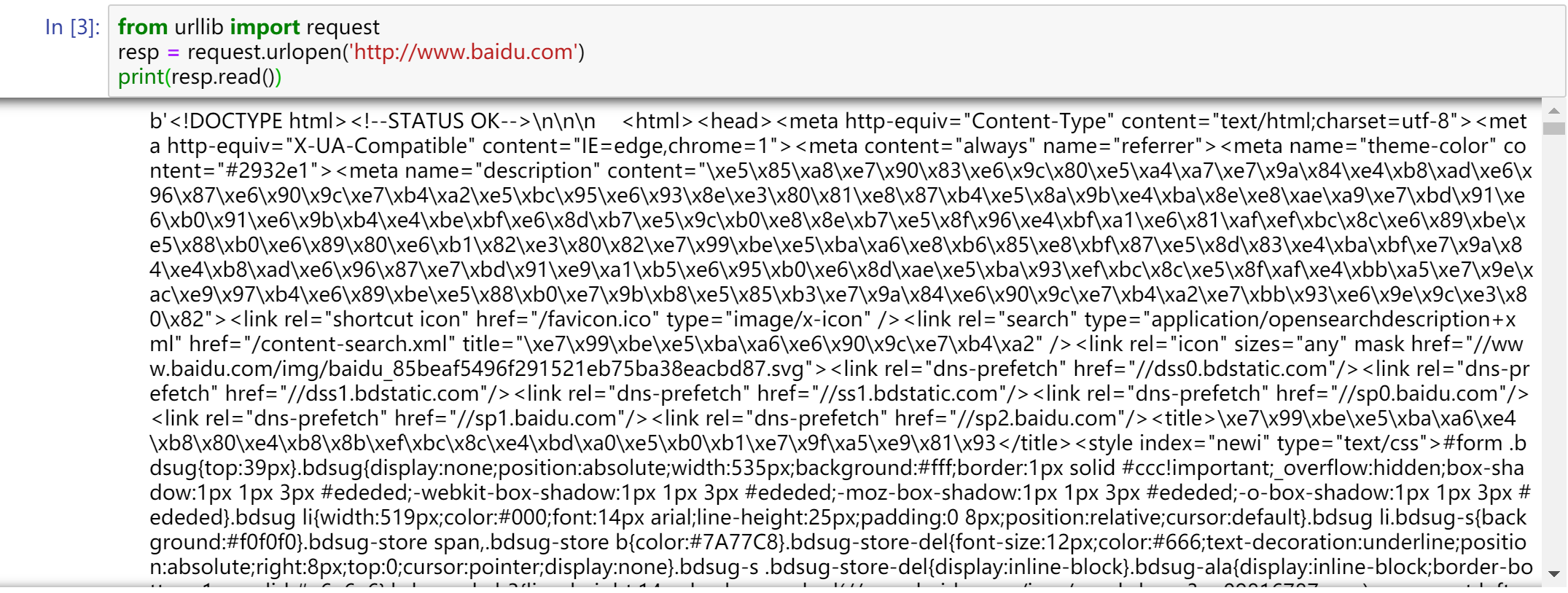
使用浏览器访问百度,右键查看源代码。你会发现,跟我们刚才打印出来的数据是一模一样的。也就是说,上面的三行代码就已经帮我们把百度的首页的全部代码爬下来了。一个基本的url请求对应的python代码真的非常简单。
urlretrieve函数:
这个函数可以方便的将网页上的一个文件保存到本地。
urlretrieve(url, filename=None, reporthook=None, data=None)
- 参数url:下载链接地址
- 参数filename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据)
- 参数reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
- 参数data:指post导服务器的数据,该方法返回一个包含两个元素的(filename, headers) 元组,filename 表示保存到本地的路径,header表示服务器的响应头
以下代码非常轻松地将百度首页代码下载到了本地
from urllib import request
request.urlretrieve('http://www.baidu.com', 'baidu.html')
urlencode函数:
用浏览器发送请求的时候,如果url中包含了中文或者其他特殊字符,那么浏览器会自动的给我们进行编码。而如果使用代码发送请求,那么就必须手动的进行编码,这时候就应该使用urlencode函数来实现。urlencode可以把字典数据转换为url编码的数据。示例代码如下:
from urllib import parse
data = {'name':'爬虫基础','greet':'hello world','age':100}
qs = parse.urlencode(data)
print(qs)

parse_qs函数:
可以将经过编码后的url参数进行解码。示例代码如下:
from urllib import parse qs = "name=%E7%88%AC%E8%99%AB%E5%9F%BA%E7%A1%80&greet=hello+world&age=100" print(parse.parse_qs(qs))

urlparse和urlsplit
有时候拿到一个url,想要对这个url中的各个组成部分进行分割,那么这时候就可以使用urlparse或者是urlsplit来进行分割。示例代码如下:
from urllib import request,parse
url = 'http://www.baidu.com/s?username=vsbf'
result = parse.urlsplit(url)
# result = parse.urlparse(url)
print('scheme:',result.scheme)
print('netloc:',result.netloc)
print('path:',result.path)
print('query:',result.query)
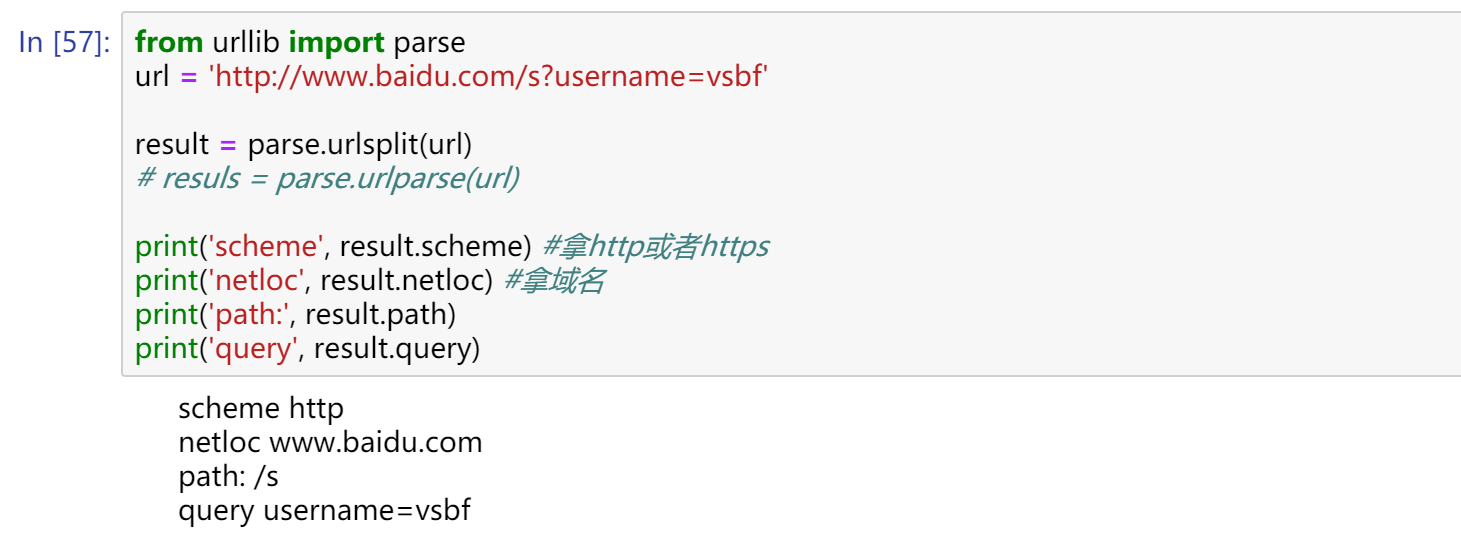
urlparse和urlsplit基本相同
request.Request类:
利用urlopen( )方法可以实现最基本请求的发起,但有时候如果我们想在请求的时候,加入一些Headers等信息,那么就必须要使用Request类,构造函数如下:
class urllib.request.Request(url, data=None, headers={ }, origin_req_host=None,unverifiable=False, method=None)
- 参数url用于请求URL,这是必传参数,其他都是可选参数
- 参数data如果要传,必须传bytes(字节流)类型的。如果它是字典,可以先用urllib.parse模块里的urlencode( )编码
- 参数headers是一个字典,它就是请求头,我们可以在构造请求时通过headers参数直接构造,也可以通过调用请求示例的add_header( )方法添加。添加请求头最常用的用法就是通过修改User-Agent来伪装浏览器
- 参数origin_req_host指的是请求方的host名称或者IP地址
- 参数unverifiable表示这个请求是无法验证的,默认是False,意思就是说用户没有足够的权限来选择接收这个请求的结果。例如,我们请求一个HTML文档中的图片,但是我们没有自动抓取图像的权限,这时unverifiable的值就是True
- 参数method是一个字符串,用来指示请求使用的方法,比如GET、POST和PUT等
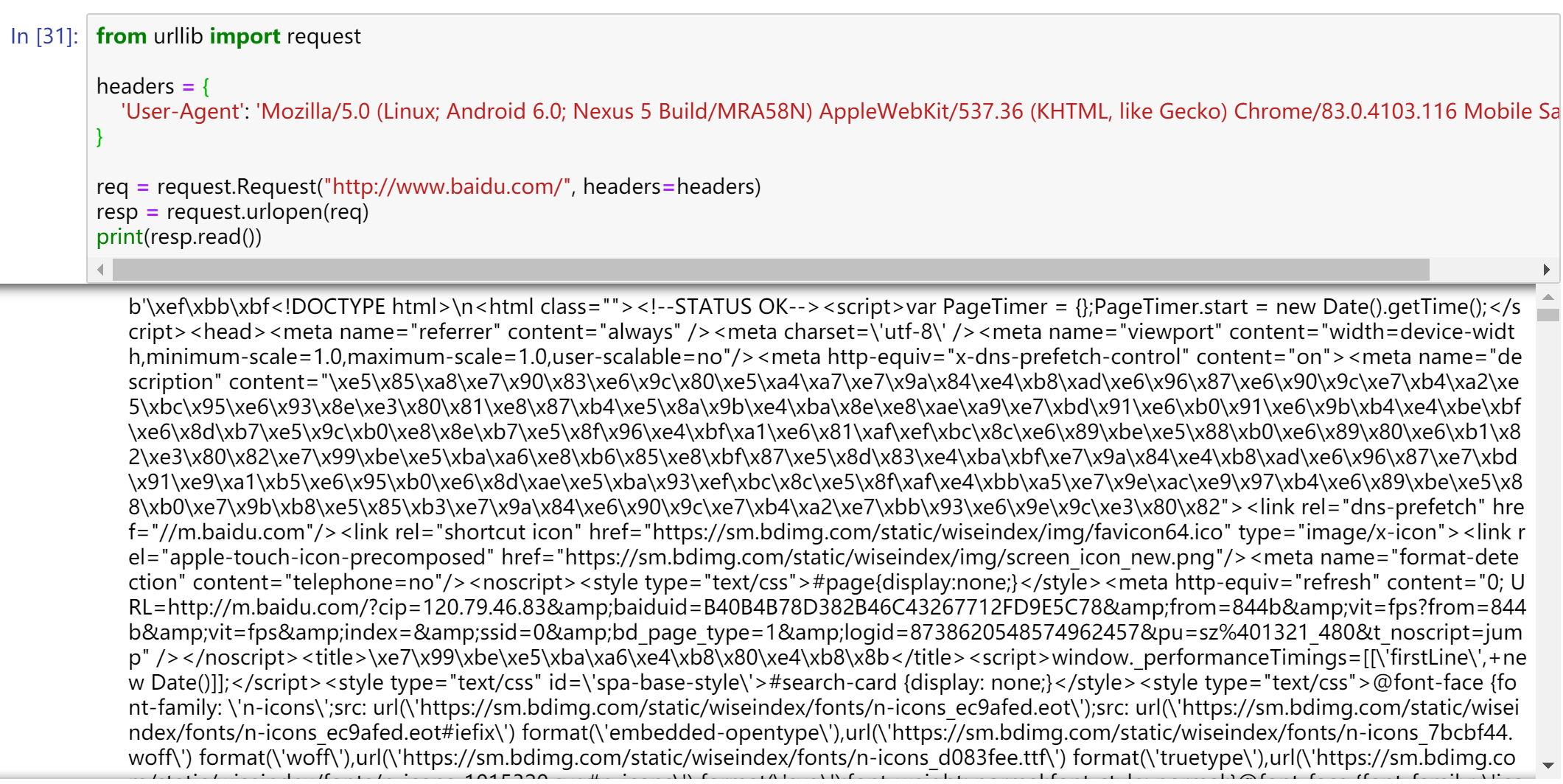
如果我们想加一个User-Agent

from urllib import request
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
req = request.Request("http://www.baidu.com/", headers=headers)
resp = request.urlopen(req)
print(resp.read())
opener类
urllib.urlopen()函数不支持验证、cookie或者其它HTTP高级功能。要支持这些功能,必须使用build_opener()函数创建自定义Opener对象:
- 使用相关的Handler处理器来创建特定功能的处理器对象
- 然后通过urllib2.build_opener()方法使用这些处理器对象,创建自定义opener对象
- 使用自定义的opener对象,调用open()方法发送请求
如果程序里所有的请求都使用自定义的opener,可以使用urllib2.install_open()将自定义的opener对象定义为全局opener,表示如果之后凡是调用urlopen,都将使用这个opener(根据自己的需求来选择)
ProxyHandler处理器(代理设置)
很多网站会检测一段时间某个IP的访问次数,如果访问次数太多,它会禁止这个IP的访问。所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换一个IP继续爬。

常用的获取代理ip的网站:
http://www.goubanjia.com/
https://www.xicidaili.com/
http://www.dailiyun.com/
http://www.kuaidaili.com/
步骤:
- 使用proxyhandler,传入代理(字典形式)构建一个handler
- 使用上面创建的handler构建一个opener
- 使用opener发送一个请求
from urllib import request
handler = request.ProxyHandler({"http" : "14.115.104.103:808"}) #创建代理
opener = request.build_opener(handler)
req = request.Request("http://www.baidu.com")
resp = opener.open(req)
print(resp.read())
如果爬不出来,就要考虑更换代理。
Cookie
啥是Cookie?
当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就是cookie,它是Internet站点创建的,为了辨别用户身份而储存在用户本地终端上的数据,cookie大部分都是加密的,cookie存在与缓存中或者硬盘中,在硬盘中的是一些文本文件,当你访问该网站时,就会读取对应的网站的cookie信息,cookie有效地提升了用户体验,一般来说,一旦将cookie保存在计算机上,则只有创建该cookie的网站才能读取它
我们如果登录了一个网站,浏览器会把我们的登录信息保存,下次再进入的时候,不需要输入账号密码,只需要读取cookie信息就好了
cookie的格式
Set-Cookie: NAME=VALUE;Expires/Max-age=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
- NAME:cookie的名字
- VALUE:cookie的值
- Expires:cookie的过期时间
- Path:cookie作用的路径
- Domain:cookie作用的域名
- SECURE:是否只在https协议下起作用
使用cookielib库和HTTPCookieProcessor模拟登录
这里以我的博客为例。在我的博客中,要访问后台,必须先登录才能访问,登录说白了就是要有cookie信息。
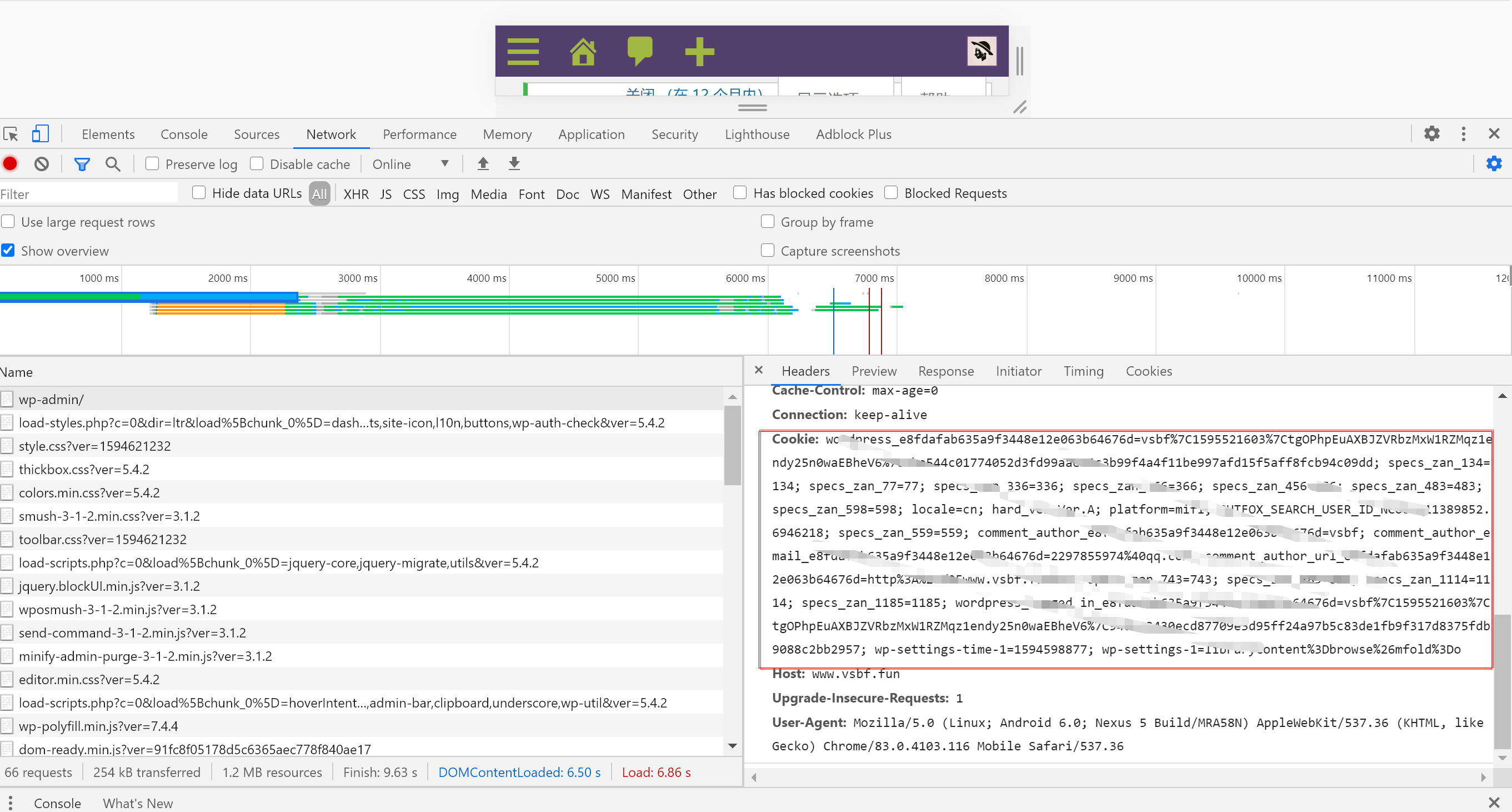
那么如果我们想要用代码的方式访问,就必须要有正确的cookie信息才能访问。解决方案有两种,第一种是使用浏览器访问,然后将cookie信息复制下来,放到headers中,示例代码如下:
from urllib import request
from ipython_genutils import encoding
headers = {
'User_Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36',
'Cookie' : '这个就算了吧,你们用自己的博客试试,嘿嘿嘿'
}
url = '自己的后台链接'
req = request.Request(url, headers = headers)
resp = request.urlopen(req)
with open('wp-admin.html','w', encoding='utf-8') as fp:
fp.write(resp.read().decode()) #将文件写入当前文件夹
所以说cookie应该是一个很重要的东西,如果你的cookie信息被泄露了...那就呵呵了
但是每次在访问需要cookie的页面都要从浏览器中复制cookie比较麻烦。在Python处理Cookie,一般是通过http.cookiejar模块和urllib模块的HTTPCookieProcessor处理器类一起使用。http.cookiejar模块主要作用是提供用于存储cookie的对象。而HTTPCookieProcessor处理器主要作用是处理这些cookie对象,并构建handler对象。
http.cookiejar模块:
该模块主要的类有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。这四个类的作用分别如下:
- CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
- FileCookieJar (filename,delayload=None,policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问访问文件,即只有在需要时才读取文件或在文件中存储数据。
- MozillaCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与Mozilla浏览器 cookies.txt兼容的FileCookieJar实例。
- LWPCookieJar (filename,delayload=None,policy=None):从FileCookieJar派生而来,创建与libwww-perl标准的 Set-Cookie3 文件格式兼容的FileCookieJar实例。
登录页面:
from urllib import request, parse
from http.cookiejar import CookieJar
headers = {
'User_Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
def get_opener():
cookiejar = CookieJar() #创建一个cookiejar对象
opener = request.build_opener(request.HTTPCookieProcessor(cookiejar)) #使用cookiejar创建一个opener对象
return opener
def login_admin(opener):
data = {'log':'账号', 'pwd':'密码'} #登录需要的数据字典
data = parse.urlencode(data).encode('utf-8') #将数据编码处理
login_url = 'http://www.vsbf.fun/xxx' #提交数据的页面
req = request.Request(login_url, headers = headers, data = data)
opener.open(req)
def visit_admin(opener):
url = 'http://www.vsbf.fun/xxx'
req = request.Request(url, headers=headers)
resp = opener.open(req)
with open('admin.html', 'w', encoding = 'utf-8') as fp:
fp.write(resp.read().decode())
if __name__ == '__main__':
opener = get_opener() #创建一个使用HTTPCookieProcessor创建一个open对象
login_admin(opener) #获取cookie
visit_admin(opener) #使用获取的cookie访问数据
data = parse.urlencode(data).encode('utf-8') ,由于我们的data中可能包含了中文或者其他特殊字符,一般来说浏览器会自动的给我们进行编码。而如果使用代码发送请求,那么就必须手动的进行编码,这时候就应该使用urlencode函数来实现,编码之后,是一个字符串的格式,还需要将其编码变成bytes格式
保存cookie到本地:
使用cookiejar的save方法,并且指定文件名:
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar("cookie.txt") #如果mozilla指定了名字,后面的sava就不用指定,否则需要指定
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
headers = {
'User_Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Mobile Safari/537.36'
}
req = request.Request(url参数 ,headers=headers)
resp = opener.open(req)
print(resp.read())
cookiejar.save(ignore_discard=True,ignore_expires=True) #忽略过期时间
从本地加载cookie:
从本地加载cookie,需要使用cookiejar的load方法,并且也需要指定方法:
from urllib import request
from http.cookiejar import MozillaCookieJar
cookiejar = MozillaCookieJar("cookie.txt") #如果这里制定了参数,load的时候就不需要指定了
cookiejar.load(ignore_expires=True,ignore_discard=True)
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'
}
req = request.Request(url参数, headers=headers)
resp = opener.open(req)
print(resp.read())
Comments NOTHING